Polyglot conda environments - 1/3 - Introduction
Table of Contents
In this series of posts we want to show how we can use conda environments for polyglot data science projects that use both R and python.
Polyglot Environments
Polyglot environments are basically environments that use more than one programming language. For data science R and
python are the most popular programming languages and most projects decide on either using one or the other. Why should
we shoulder the extra effort of using R and python on the same project? Well there could be plenty of reasons:
- Inclusiveness, you can include new team members that come from the other language more quickly.
- Reusability, if you already have solved similar problems in the other language you can reuse the code.
- Capability, you increase the number of tools and packages that you can use for your project.
Your typical data science environment does not only include the code that you write but also the software that is installed on you computer including the operating system as well as the hardware it is running on. Typically it also consists of a data interface through which your data is loaded onto your system and a reporting interface that communicates the results of your analysis.
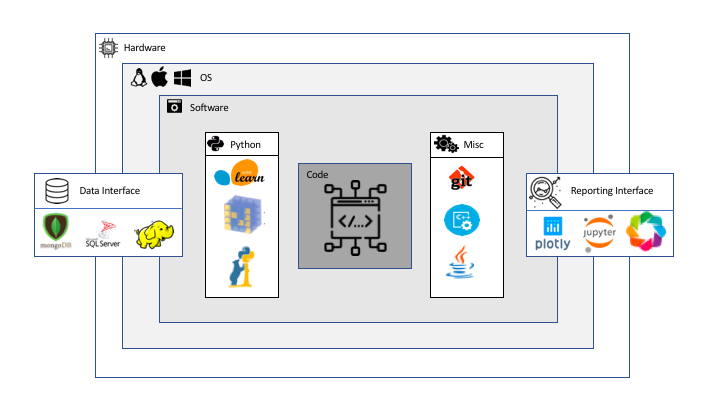
In fact most data projects are already openly polyglot because they include SQL code to call data from database via the data interface (the database drivers). But even if they are not underneath the hood the interfaces and the packages you have installed will be using a variety of other programming languages so technically the primary language that you chose for you data project is primarily glue code for all the other languages that you are implicitly using.
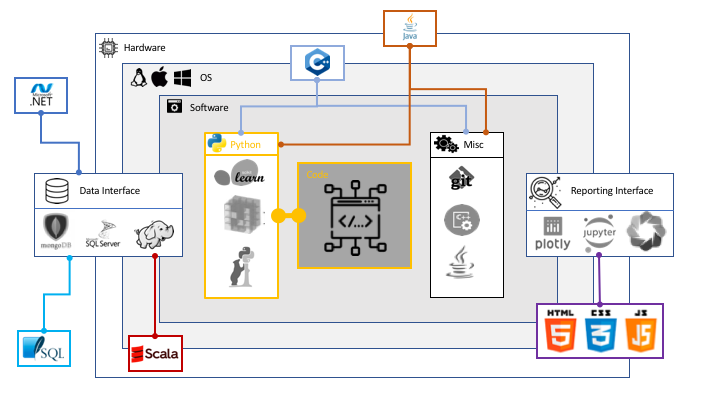
Both R and python make it easy for you to put your code in packages and to add documentation
and unittests. So using a second language can basically be seen as using yet another package.
Simply put the code of the secondary language into functional units that in the end require
minimal, easily readable code when called. Add some tests and documentation so also team members
that are inexperienced in the secondary language can understand, use and trust its code.
Reproducibilty
Reproducibility is a challenge for each data science project. As illustrated before data science environments are not isolated entities that run independently by themselves but they are often connected to other systems from where they gather there data and to which they transmit their results to. Therefore a variety of dependencies exist that are needed for the code to run properly.
Dependencies
Code dependencies
These are the obvious dependencies which are easily avoided by adhering to good coding practices.
- file paths
- random numbers or randomized code outcome
Software dependencies
A typical data science project can depend on a number of installations on your machine. To name a few of them
R*R packages*python*python packages*pipgitJavaa C++ compilerpandoclatexphantom js- database drivers
The most important being R and python and the underlying packages which usually shoulder the workload of your code.
System/Hardware dependencies
Then there is you machine in itself which has a specific get up:
- OS (32bit, 64bit)
- environment variable
- Hardware (number of cores, RAM, GPU)
Connectivity dependencies
- Data interface (database drivers, clients to connect to Big Data infrastructure, REST API calls)
- Output interface (html reports, BI tools, git commit and push)
Strategies
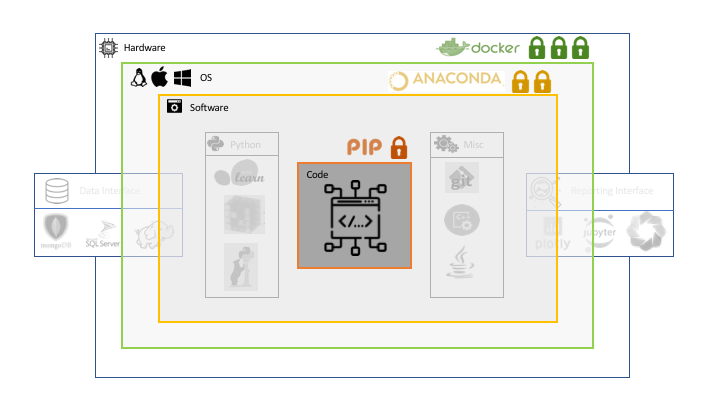
Programming language-based solutions
There are a number of strategies to reproducibly preserve either your python or your R installation. For R there is packrat and checkpoint and for python there is the pip freeze command, which preserves all packages and version in a requirements.txt file.
However these solutions are focused on snapshotting the programming language installation and do not consider any of the other tools and system configurations that might be necessary to run your code.
Environment-based solutions (anaconda/conda)
conda environments use a bit of a more holistic approach and strive to encapsulate apps and programming languages including the packages. They provide a strategy for handling R and python simultaneously and they have a set of packages for which they offer their own support for. Meaning you can download the packages from a conda server and they are garanteed to be compatible with each other as long as they are being installed at the same time. However the conda environments are not garanteed to be platform independent. The list of supported packages depends on the OS. However anaconda will make an effort to replicate the environment as closely as possible.
Container-based solutions
The state of the art solution is a docker container, which containerizes everything (tools, drivers, environment variables, etc), this eases pushing code into procuction as explained here. There are even solutions for systems with specialized hardware configurations such as GPUs, as explained here
conda environments
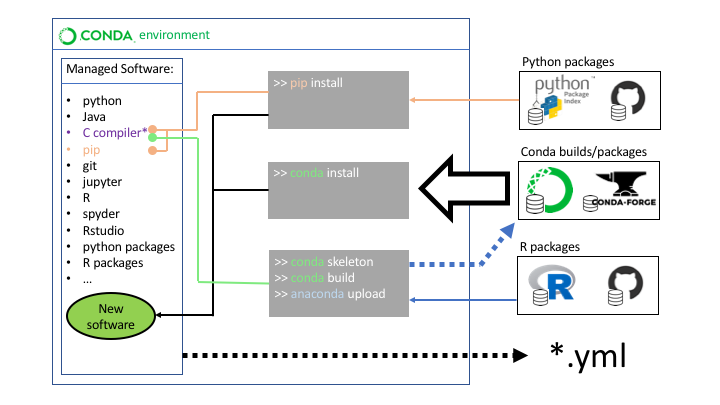
conda environments are very popular among python users. python packages are distributed on Pypi and are uncompiled,
thus installing the most common datascience packages can be quite tricky because there are a lot of things that can go wrong
when compiling code.
conda allows you to create different environments on your hard drive that are independent from each other and into which
all kind of software can be installed and it is not limited to python. For software to be installed into a conda environments
it needs to be available as a precompiled conda build for the OS at hand on one of the official conda servers. Before
installing the new software conda will check whether all dependencies of the new package are already installed
or available on the conda servers. It will also check whether there might a dependency conflict with software that
is already installed. If all software that needed is available through conda sources the environment can easily
be recreated on another system with the same operating system by simply exporting a list of all the software that is installed.
python packages
If python packages cannot be found on conda servers they can simply be installed via pip when called from within the activated conda environment. conda will use its internal compiler if the package needs compilation. This is a bit risky because the compilation step might not be as easily reproducible on another system.
R packages
We can install R packages if there are not available from conda sources by making our own conda builds. conda will create a build recipe based upon the information it finds on CRAN and then will use the internal compiler to create a conda build which then can be uploaded to a conda server from which it can be retrieved and installed. This is a bit tedious because for this to work we need to have already preinstalled all dependencies for a given packages. Thus we need to find the packages with no or few dependencies and work our way up. It might be frustrating to start this process but it will almost always work. You can find detailed instructions in the next post.